Logstash
Contents
Logstash¶

Centralize, transform & stash your data¶
Logstash is a free and open server-side data processing pipeline that ingests data from a multitude of sources, transforms it, and then sends it to your favorite “stash.”

Inputs¶
Ingest data of all shapes, sizes, and sources¶
Data is often scattered or siloed across many systems in many formats. Logstash supports a variety of inputs that pull in events from a multitude of common sources, all at the same time. Easily ingest from your logs, metrics, web applications, data stores, and various AWS services, all in continuous, streaming fashion.

Filters¶
Parse & transform your data on the fly
As data travels from source to store, Logstash filters parse each event, identify named fields to build structure, and transform them to converge on a common format for more powerful analysis and business value.
Logstash dynamically transforms and prepares your data regardless of format or complexity:
Derive structure from unstructured data with grok
Decipher geo coordinates from IP addresses
Anonymize PII data, exclude sensitive fields completely
Ease overall processing, independent of the data source, format, or schema.

Outputs¶
Choose your stash, transport your data While Elasticsearch is our go-to output that opens up a world of search and analytics possibilities, it’s not the only one available.
Logstash has a variety of outputs that let you route data where you want, giving you the flexibility to unlock a slew of downstream use cases.

Extensibility¶
Create and configure your pipeline, your way¶
Logstash has a pluggable framework featuring over 200 plugins. Mix, match, and orchestrate different inputs, filters, and outputs to work in pipeline harmony.
Ingesting from a custom application? Don’t see a plugin you need? Logstash plugins are easy to build. We’ve got a fantastic API for plugin development and a plugin generator to help you start and share your creations.
Read the docs¶
https://www.elastic.co/guide/en/logstash/current/introduction.html
Introduction¶
Logstash is an open source data collection engine with real-time pipelining capabilities. Logstash can dynamically unify data from disparate sources and normalize the data into destinations of your choice. Cleanse and democratize all your data for diverse advanced downstream analytics and visualization use cases.
While Logstash originally drove innovation in log collection, its capabilities extend well beyond that use case. Any type of event can be enriched and transformed with a broad array of input, filter, and output plugins, with many native codecs further simplifying the ingestion process. Logstash accelerates your insights by harnessing a greater volume and variety of data.
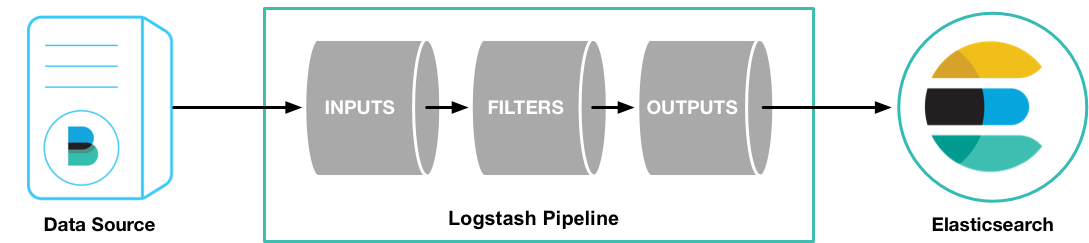
Configuration¶
Pipelines¶
A conf file is a configuration for a pipeline.
# This is a comment. You should use comments to describe
# parts of your configuration.
input {
...
}
filter {
...
}
output {
...
}
Settings¶
logstash.yml is the setting file YAML format containg control general options for the execution
https://www.elastic.co/guide/en/logstash/current/logstash-settings-file.html
pipeline:
batch:
size: 125
delay: 50
Twitter Input Plugin¶
https://www.elastic.co/guide/en/logstash/current/plugins-inputs-twitter.html
input {
twitter {
consumer_key => "xxx"
consumer_secret => "yyy"
oauth_token => "zzz"
oauth_token_secret => "www"
keywords => ["#novax","#moderna","Calenda"]
full_tweet => true
}
}
output
{
stdout {}
}
Logstash on Docker¶
Elastic provides a ready to use image
docker pull docker.elastic.co/logstash/logstash:8.1.0
Run¶
Create a pipeline directory with config and run container mounting the config
docker run --rm -it -v $PWD/pipeline/:/usr/share/logstash/pipeline/ docker.elastic.co/logstash/logstash:8.1.0